cover picture sponsor: gleammming.art
在變數(variable)的章節,我們已經學習怎麼宣告變數並且存取變數裡面的值,眼尖的你或許會發現賦予變數的值中有數字、文字……等等不同的資料類型,而這些不同的類型我們稱呼他為資料型別(data types)。
你有發現上章節中的變數中我們曾經賦值過
Gorilla!這串文字嗎?
在認知心理學中的注意力(attention)研究領域裡,普遍認為是注意力是有 選擇性 的,而其中一個著名的實驗叫做 看不見的大猩猩實驗(Invisible Gorilla Test)。
在大猩猩實驗中,受試者被要求觀看一則僅只有一分多鐘的 短片,並被要求數出影片中白衣男子傳球的次數。
而經由 Simons、Chabris(1999)實驗指出有半數的受試者沒有發現影片中出現了一個身穿大猩猩服裝的演員,而那隻猩猩甚至在短片中長達 9 秒多中的停留時間。
後來 Simons 稱這種現象為 不注意視盲(Inattensional blindness),意思即為當我們注意力放在其他焦點上時,其他的細節的部份可能會被我們省略。所以當你在專注於 var、=,; 這些符號與記憶體地址上的概念時,你很有可能就會忽略掉 Gorilla! 這串文字。
而透過這個研究結果我想傳達的想法是,以往你閱讀程式時可能已經熟稔於它的 執行結果,但從這章節中開始到第二章節結束前,你不僅得要將注意力放在這些「符號」的樣子,還要停下來幾秒鐘的時間,試著揣摩這些「細節」對於電腦來說到底意味著什麼。
在 JavaScript 當中,資料型別主要可以分為 原始型別 以及 非原始型別:
原始型別(primitive types)
'' 、雙引號 "" 所包起的文字內容。0、-1、100、10000 ……等等。true 以及 false。undefined
null
物件型別(object types):又可稱為非原始型別(Non-primitive types)
上方類別中又可分為字串、數字等等類型,這個區分主要是牽扯到型別上的定義以及資料相對可操作的方法(methods)有哪些,而這些內容可參考 w3schools 中的教學來練習:
字串、數字、物件這些原本不就是資料類別了嗎?為何還要區分出兩種大的類型?
上面提及的原始型別與非原始型別除了一些細微的差異外,最大的差異在於透過變數賦值時的參考機制不太相同。
當我們今天透過變數賦值給另一個變數,若該變數的資料型態為 原始型別 時:
var boxA = 1
var boxB = 2
boxA = boxB // 透過變數賦值,而該變數所儲存的是原始型別
console.log(boxA) // ???
console.log(boxB) // ???
一開始在執行期的創造階段時會分配一個記憶體地址:
var boxA
var boxB

接著執行期的執行階段,開始一行一行讀取程式,接著將值存於該記憶體位置中:
boxA = 1
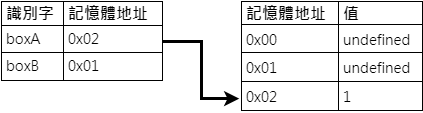
boxB = 2
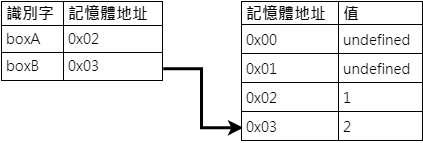
接下來在第三行 boxA = boxB 中,我們依據變數章節時提過的 找址(LHS) 與 找值(RHS) 概念解釋:boxA = boxB 是在告訴解析器說:請它先找到 boxB 所參考記憶體地址的值(2)接著再將這個值賦值給 boxA。
此時由於 2 為 原始型別,因此解析器會選擇另開一個記憶體位置給 boxA,並且把 2 同時賦值進去。
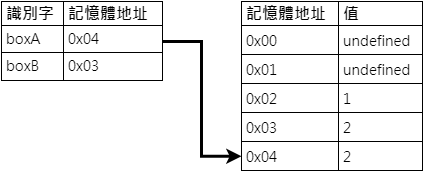
因此最後 console.log(boxA) 會在開發者工具列上顯示位於 0x04 記憶體地址中的 2;而 console.log(boxB) 會顯示位於 0x03 記憶體地址中的 2。
當我們今天透過變數賦值給另一個變數,若該變數的資料型態為 物件型別 時:
var boxA = 1
var boxB = {}
boxA = boxB // 透過變數賦值,而該變數所儲存的是物件型別
console.log(boxA) // ???
console.log(boxB) // ???
同樣的,一開始在執行期的創造階段時會分配一個記憶體地址:
var boxA
var boxB

在執行階段中的第一行、第二行時也是一模一樣,只是賦的值稍微不同而已:
boxA = 1
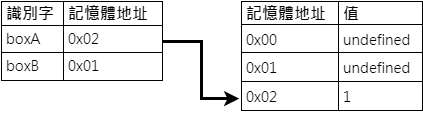
boxB = {}
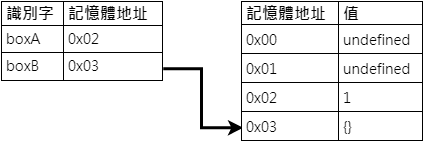
接下來看到第三行 boxA = boxB,這次與上方不同的地方在於 boxB 的值是一個 物件型別,因此這次解析器是選擇將 boxA 的記憶體位置指向了 boxB 的記憶體位置,也就是 0x01。
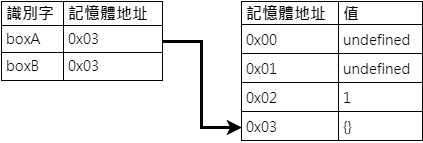
現在 boxA 與 boxB 都指向了 0x03,所以當程式執行到最後一行 console.log(boxA) 時,所找到的值自然為 0x03 中的 {}。
我們將前面「變數章節」提過的內容與這章節的情形比較一下:
第一種情形:若將值直接賦值給變數時,不論其資料型別為何,都會指向到新的記憶體。
var box; // 0x00 => undefined
box = 1; // 0x01 => 1
box = {}; // 0x02 => {}
box = []; // 0x03 => []
console.log(box); // 0x03 => []
第二種情形:若透過變數賦值,如果來源資料為原始型別,則指向新的記憶體。
var boxA = 1; // 0x00 => undefined, 0x02 => 1
var boxB = 2; // 0x01 => undefined, 0x03 => 2
boxA = boxB; // 0x04 => 2
console.log(boxA); // 0x04 => 2
console.log(boxB); // 0x03 => 2
第三種情形:若透過變數賦值,如果來源資料為物件型別,則會將變數的參考地址改為賦值變數的記憶體地址。
var boxA = 1; // 0x00 => undefined, 0x02 => 1
var boxB = {}; // 0x01 => undefined, 0x03 => {}
boxA = boxB; // 0x03 => {}
console.log(boxA); // 0x03 => {}
console.log(boxB); // 0x03 => {}
現在你已經瞭解了三種不同的賦值情形,現在來一起練習預測看看程式碼的執行結果與對應的記憶體是誰:
var boxA = 1;
var boxB = {};
var boxC = boxA;
boxA = boxB;
console.log(boxA);
console.log(boxB);
console.log(boxC);
上面提到了賦值的三種情況,接下來我們來試著理解賦值與修改物件之間的差別。
賦值時的情境:
var boxA = {origin: 'A'}; // 0x00 => undefined, 0x02 => {origin: 'A'}
boxA = {origin: 'Raw'}; // 0x03 => {origin: 'Raw'}
console.log(boxA); // 0x03 => {origin: 'Raw'}
上方程式碼就如同賦值三種情況的第一種一樣,直接賦值時會分配一個新的記憶體地址,因此最後 boxA 自然而然是指向了新的記憶體位置 並且顯示 {origin: 'Raw'}。
修改物件時的情境:
var boxA = {origin: 'A'}; // 0x00 => undefined, 0x02 => {origin: 'A'}
boxA.origin = 'Raw'; // 0x02 => {origin: 'Raw'}
console.log(boxA); // 0x02 => {origin: 'Raw'}
在修改物件時的情境時,最後 console.log 的結果也是 {origin: 'Raw'},但這邊不一樣的是第二行中我們是透過點語法來賦值 boxA 中 origin 屬性的值。
所以實際上 boxA.origin 在解析器搜索時,它會先找到 0x02 記憶體中的物件 {origin: 'A'} 接著才修改裡面的屬性,所以它並沒有分配一個新的記憶體位置給它。
延伸閱讀:透過 抽象語法樹 觀察兩者差異
當我們是透過
boxA來賦值時,對於解析器來說它是對Identifier(識別字)賦值一個ObjectExpression(物件運算式),而當我們透過boxA.origin操作時,對解析器來說它對MemberExpression(成員運算式)中的值進行修改,也就是說這兩種賦值方式對於 JavaScript 是有區別的。
現在我們來練習預測下列程式碼的運行過程與結果:
var boxA = {'origin': 'A'};
var boxB = boxA;
boxA.origin = 'changeViaB';
console.log(boxA); // ???
console.log(boxB); // ???
var boxA = {'origin': 'A'};
var boxB = {'origin': 'B'};
var boxC = boxA;
boxA = boxB;
boxB = {'origin': 'changeViaB'}
console.log(boxA); // ???
console.log(boxB); // ???
console.log(boxC); // ???
若你可以順利的解釋過程與結果,那麼表示你已經瞭解資料型別對於賦值上的影響了!
若還是有遇到問題的話,不彷透過繪製記憶體圖表來觀察是否再哪個步驟上理解時遇到困難!
目標:

